CodeQL 若干问题思考及 CVE-2019-3560 审计详解
1. 背景
CodeQL 是一个白盒源代码审计工具,去年在这一领域掀起了一些波澜。其开发公司 Semmle 也成功和 Github 联姻,成立了 Github Security Lab,负责 Github 上开源软件的代码安全审计。同时还推出了面向社区和企业的源代码分析服务平台 LGTM,一派生机勃勃的景象。不过国内安全社区对 CodeQL 似乎还没有足够的讨论,网上零星有几篇文章也主要是安装配置和简单上手体验。
那么,CodeQL 有哪些核心能力?安全从业者能怎样运用它?它能给企业带来更大的价值吗?等等。这些都是我初见 CodeQL 时产生的疑问。在这篇文章中,我将从实际落地应用的角度出发,通过对一个漏洞实例的具体审计分析思路溯源来展示白盒审计中的一些关键问题,进而谈谈我对于 CodeQL 若干问题的个人看法。
2. CodeQL 工作流程
CodeQL 的整体工作流程如下图所示: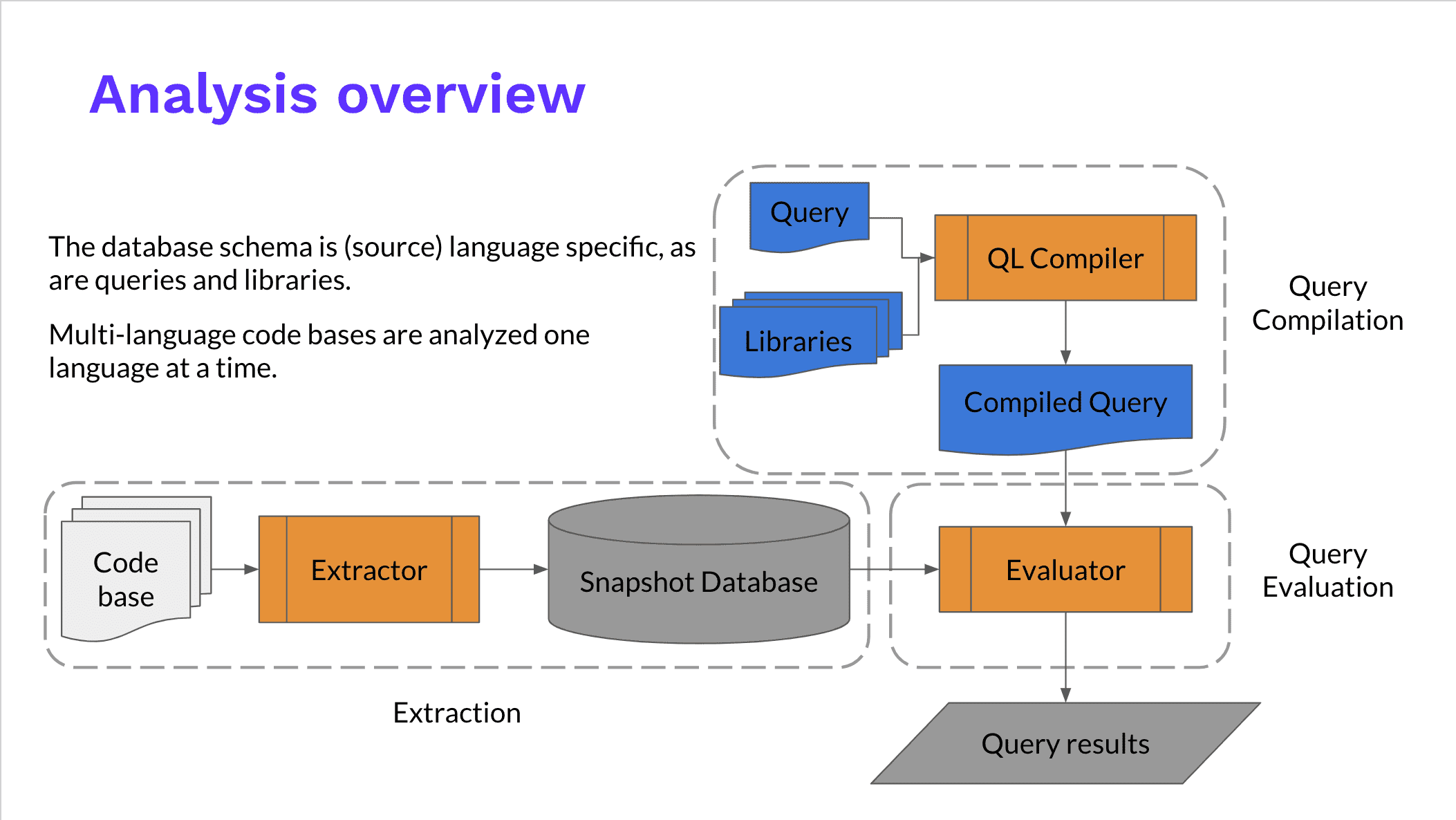
(图片来源:https://blog.semmle.com/introduction-to-variant-analysis-part-2/)
CodeQL 的整体思路是把源代码转化成一个可查询的数据库,通过 Extractor 模块对源代码工程进行关键信息分析提取,构成一个关系型数据库。CodeQL 的数据库并没有使用现有的数据库技术,而是一套基于文件的自己的实现。
对于编译型语言,Extractor 会监控编译过程,编译器每处理一个源代码文件,它都会收集源代码的相关信息,如:语法信息(AST 抽象语法树)、语意信息(名称绑定、类型信息、运算操作等),控制流、数据流等,同时也会复制一份源代码文件。而对于解释性语言,Extractor 则直接分析源代码,得到类似的相关信息。
关键信息提取完成后,所有分析所需的数据都会导入一个文件夹,这个就是 CodeQL database, 其中包括了源代码文件、关系数据、语言相关的 database schema(schema 定义了数据之间的相互关系)。
接下来就可以对数据库进行查询了,CodeQL 自己定义实现了一套名为 QL 的查询语言,并提供了相应的支持库和运行环境。
最终将查询结果展示给用户,方便用户进行进一步的人工审计分析。
3. CodeQL 构成概述
CodeQL 的核心功能主要涉及两个工程:
codeql-cli-binaries:
https://github.com/github/codeql-cli-binaries
ql:
https://github.com/Semmle/ql
codeql-cli-binaries 工程是 CodeQL 的命令行工具,实现了 CodeQL 的大部分核心功能,包括 Extractor(不同目标语言对应着不同的 Extractor)、中间语言转换、AST 提取、控制流分析、数据流分析等,这个工程的核心模块都只提供 binary,并不开放源代码。
ql 工程是 QL 查询语言的实现,QL 是一种面向对象的高级语言,其支持库中封装了程序分析所需的所有对象及常用方法。这个在下个章节的漏洞实例审计分析中会使用到。
另外还有两个不太重要工程:
vscode-codeql:
https://github.com/github/vscode-codeql
vscode-codeql-starter:
https://github.com/github/vscode-codeql-starter
vscode-codeql 是 CodeQL 的 VS Code 插件,它主要是为了方便在 VS Code 做结果展示用的; vscode-codeql-starter 工程是配合 VS Code 使用的一个 Workspace,它主要是为了方便配置,用户也完全可以自己配置 Workspace。
4. CVE-2019-3560 审计详解
关于 CodeQL 工具的安装配置,QL 开发环境的配置等内容,这些都不算是问题,本文就不赘述了。在这一部分中,我将详细分析一下 CVE-2019-3560 的审计思路。
4.1. 漏洞简介
CVE-2019-3560 是 Semmle 研究员 Kevin Backhouse 发现的一个 Facebook Fizz 公共库的整数溢出漏洞,Fizz 是 Facebook 自己的 TLS 协议开源实现,使用 C++ 编写,大量应用于 Facebook 的网络基础设施中,具有重要的意义。
虽然这个漏洞只能造成 DoS 效果,但是是由于攻击者可以以极小的成本直接打服务端,使得使用了 TLS 协议的服务直接瘫痪,Facebook 仍为这个漏洞支付了一万美元的奖金。
4.2. 漏洞成因
漏洞发生在 PlaintextRecordLayer.cpp 42 行的 += 操作,这里有一个整数溢出问题:
1 | 38 auto length = cursor.readBE<uint16_t>(); |
这段代码是如下函数的核心部分:
1 | folly::Optional<TLSMessage> PlaintextReadRecordLayer::read(folly::IOBufQueue& buf) |
它是 TLS 记录层的一部分实现,buf 是由客户端传来的网络数据。
38 行从传入的网络数据包中读取了一个 uint16_t 值,并赋值给 length,也就是说 length 是攻击者可控的。uint16_t 是一个 unsigned short int, 大小是 2 bytes,取值范围是 0~65535(0~0xFFFF);
42 行 ContentType 是一个枚举值,数据类型是 uint8_t,1 bytes,ProtocolVersion 也是枚举值,数据类型是 uint16_t,2 bytes,所以:
1 | sizeof(ContentType) + sizeof(ProtocolVersion) + sizeof(uint16_t) = 5 bytes |
由于 length 攻击者可控,则令 length == 0xFFFB 即可使 length 发生整数溢出,使得 length 结果为 0:
1 | usinged long (0xFFFB + 0x05) = usinged short (0x00) |
43 行 buf 是一个 folly::IOBufQueue 对象,这里调用了它的 trimStart 方法,其作用是向后移动 buf 数据指针。
整体这段代码在一个 while 循环里,通过 trimStart 不断向后移动数据指针来完成对 buf 中数据的处理。
39 行是一个边界检查,判断指针有没有移动到 buf 末尾,如果已经到了末尾,则表示数据处理完成,直接返回退出循环。
结合 42 行,如果 length 为 0,则 trimStart 操作无法移动 buf 指针,这样整段代码就会一直处理当前数据块,死循环了。
4.3. 构建 CodeQL 数据库
在进行 CodeQL 审计之前,我们需要构建目标程序的数据库。这里只说明一下其中的两个关键点。
编译有漏洞的 Fizz 库:
这个漏洞补丁的 revision id 是 40bbb16,我们可以 checkout 切换到它的上一次提交的代码来编译。
创建 CodeQL 数据库:
1 | codeql database create <database_path> --language=cpp --command='<build_command>' |
这样 CodeQL 就会调用编译命令去编译目标工程,同时监控编译过程,调用 CPP 的 Extractor 去提取相关信息。
4.4. CodeQL 漏洞建模
通过上面的分析可以知道,42 行处进行了一个长整型到短整型的赋值运算,如果 length >= 0xFFFB,就会发生整数溢出,导致死循环。
那么,问题的关键点就是:如何判断 length 是否是攻击者可控?
4.4.1 建模思路
我们来看一下 CodeQL 是如何找到这个用户可控的输入点的。
CodeQL 具有污点分析的能力,即如果我们能定义一个输入点 source,一个目标点 sink,就可以借助 CodeQL 去判断这两点之间是否存在数据流通路。
这里 sink 是一个整数溢出的模式,比较好定义,大整型转小整型、有符号转无符号等情况,都有可能出现整数溢出的问题。
source 就比较难定义了,我们需要定义一个模型来找出用户输入能够控制到的变量,这就要更具审计目标工程的具体实现来确定了。
具体到 Fizz,它使用了 Facebook 的一个基础 C++ 类库 folly,使用了 folly::IOBufQueue 来存储接收到的网络数据,所以比较直接的思路是将 folly::IOBufQueue 对象定义为 source。
不过 semmle 的研究员给出了一个更通用的思路,在 Fizz 的场景下,网络数据是不安全的输入,那么问题就转化为了如何准确定义网络接收的数据?当数据通过 socket 发送时,通常是以 network byte order 发送的,服务端在接收到之后,需要转换为 host bytes order,这一般是通过 ntohs/ntohl (Network to Host Short/Long) 函数实现的。network byte order 是小端序,x86 架构下的 host byte order 是大端序,即 host 在接收到网络发来的数据后,需要将其从小端序转换为大端序。Fizz 工程中并没有调用标准库的 ntohs/ntohl 函数来实现这一功能,而是调用的 folly 基础类库的 folly::Endian::big 函数来实现,功能相同。所以,我们就可以将 folly::Endian::big 函数的调用定义为 source,即做了大小端转换的操作的数据基本可以认为是接收的网络数据。
4.4.2 QL 建模实现
接下来就需要用 CodeQL 的查询语言 QL 来描述我们定义的模型。
首先导入需要用到的库:
1 | import cpp |
这里用到了 cpp 核心库、污点跟踪库、中间语言库、数据流分析库。
接着定义 folly::Endian::big 函数的匹配方法:
1 | class EndianConvert extends Function { |
通过 folly::Endian::big 函数的匹配来定义网络数据:
1 | predicate isNetworkData(Instruction i) { |
再定义一个判断危险整型转换的方法:
1 | predicate isNarrowingConversion(ConvertInstruction i) { |
注意,这里就体现出了中间语言表示的价值,通过中间语言的统一表示,我们可以用 CodeQL 库里的 ConvertInstruction 来统一匹配所有类型的数据转换操作。
再通过上面的判断方法来定义污点分析的 source 和 sink:
1 | class Cfg extends TaintTracking::Configuration { |
最终做查找和输出:
1 | from |
这里最核心的判断是通过污点分析来判断我们定义的 surce 和 sink 之间是否有数据流通路。
通过这个查询,可以在 Fizz 工程中找到筛选出三个问题,如下图所示:
其中,第三个就是 CVE-2019-3560 的漏洞点。
5.总结
写到这里,我们对 CodeQL 已经有了一个比较具体的认识。在这一部分,我想通过几个直截了当的问题来对 CodeQL 做一个大致的总结。
CodeQL 的这些能力是它独有的吗?
当然不是。白盒代码审计并不是新的领域,业界已经有非常多的工具。老牌商业软件如 Fortify SCA, Coverity,开源工具更多,各大互联网公司也都会建设自己的源代码安全审计平台,这里就不一一列举了。以 Fortify 为例, 其产品白皮书中就说明了它的五大主要分析引擎:数据流、语义、结构、控制流、配置流。各家也都在做,学术界研究的也不少。CodeQL 有什么优势?
简单说就是免费、开源、Semmle 团队强大的研究能力。Semmle 孵化于牛津大学, 其投资者包括 Google, Microsoft, NASA 等,现在又加入了 Github,这样闪光的履历其实也是能力的背书。具体讲,CodeQL 的基础功能扎实,迭代迅速,又不断有研究员发高水平的文章,这些都是它的优势。CodeQL 能给白盒领域带来突破性的发展吗?
这个不一定。从本文的漏洞实例分析中你也可以看出,白盒审计最重要的能力是对安全模型的认识和对分析目标的理解。傻瓜一键式的工具是不存在的,或者换种说法,简单问题现有工具就能解决了。所以核心还是人。CodeQL 对我们有什么价值?
分两方面。
对个人而言,意味者被赋能了更复杂的代码分析能力。越是困难的问题,基础工具的能力越是重要,这在各个领域都是相通的。比如在二进制软件分析领域,近年来在 Intel PT 技术等基础能力的加持下,就有了非常迅速的发展。
对企业而言,目前互联网公司的白盒代码审计多是采用采购商业软件 + 自研工具的方式,那我认为 CodeQL 当然是一个很重要的技术选型目标。CodeQL 更适用于哪些场景?
更适用于对复杂安全问题的建模。Fortify 之类的老牌商业软件更重要的是它的规则库,更适合做大规模、通用型问题的扫描。CodeQL 当然也可以这样用,但我认为它更适合的场景是做复杂安全问题的建模,在对审计目标有足够理解的基础之上做针对性的安全分析。